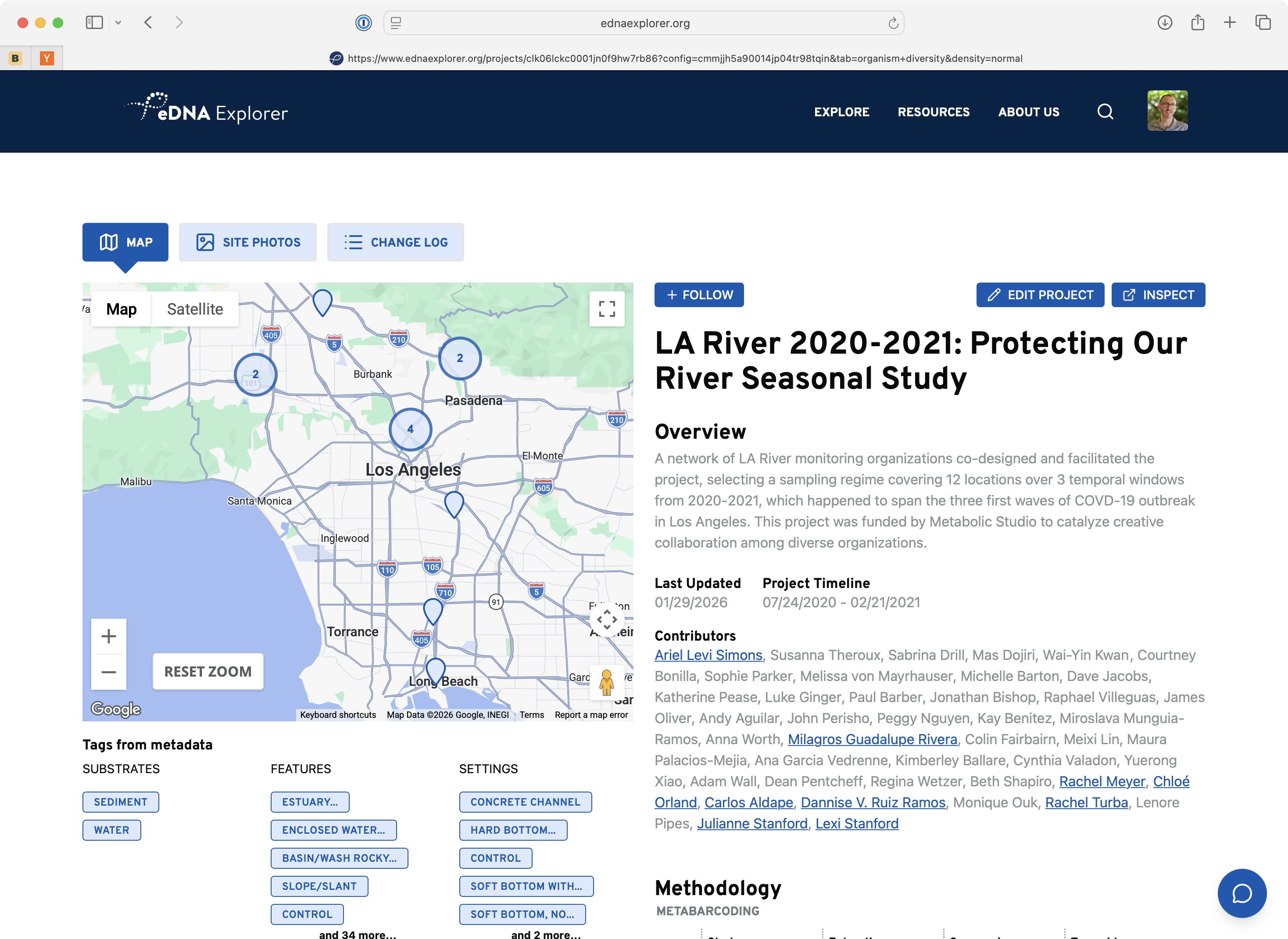
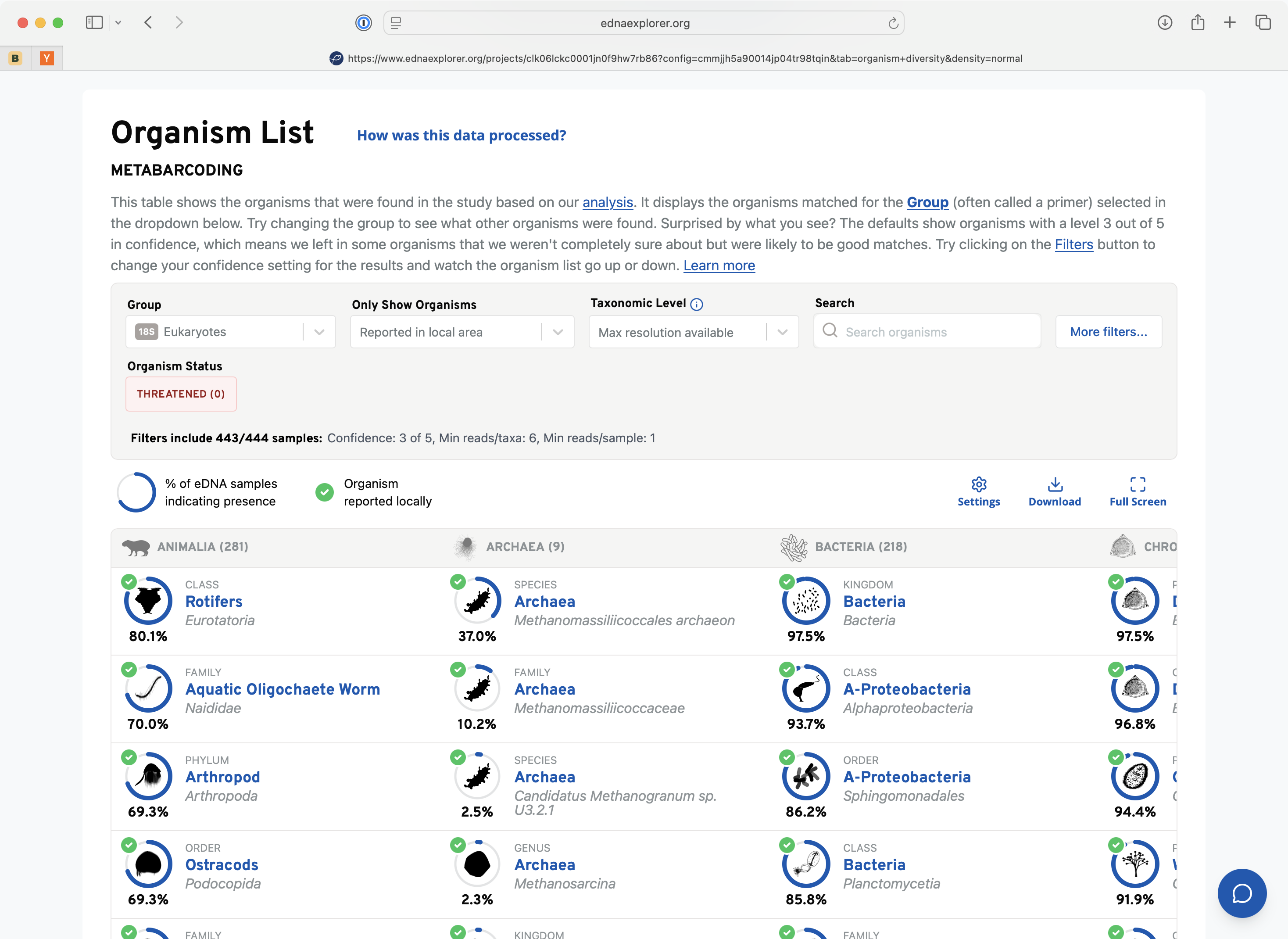
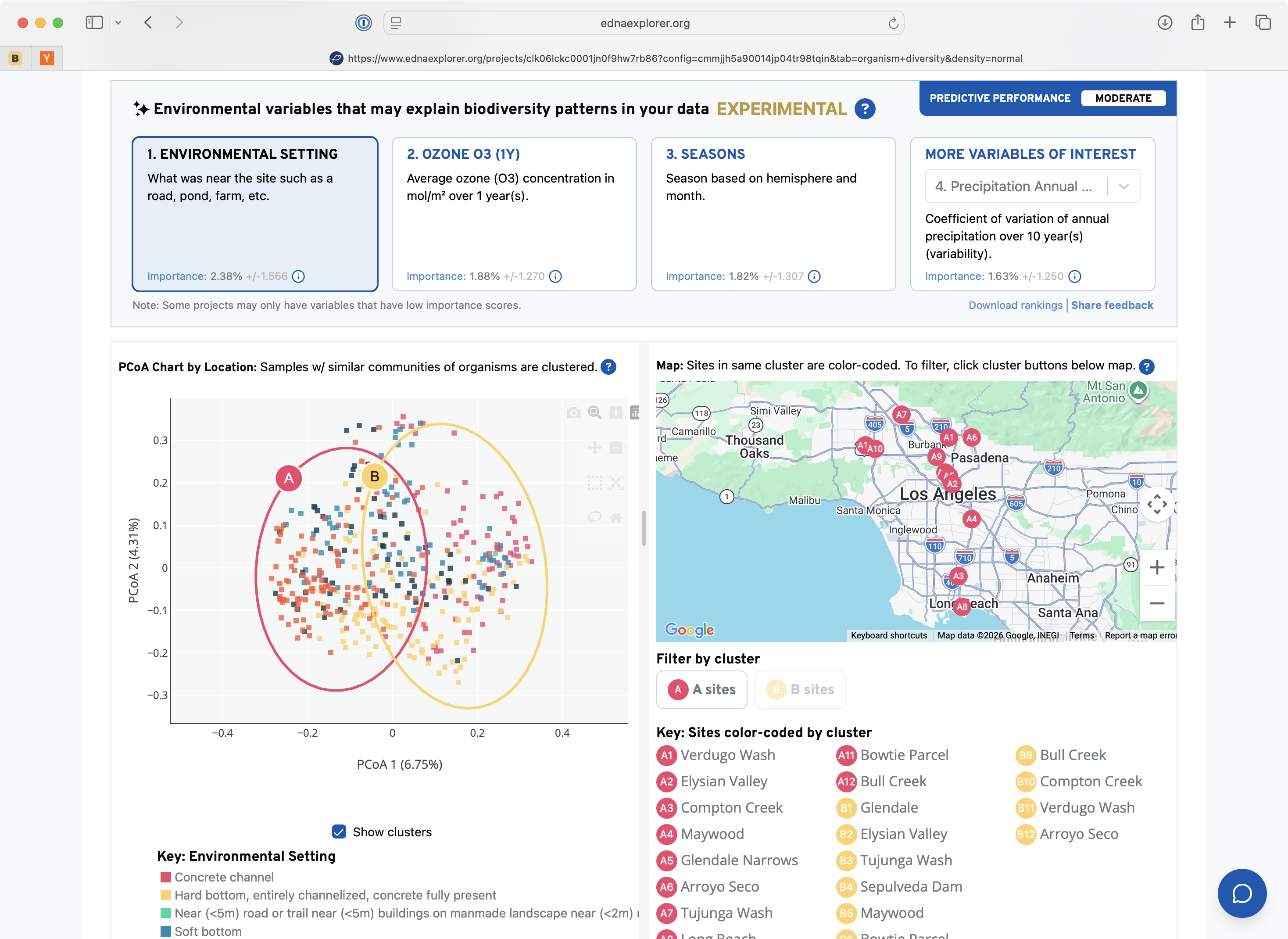
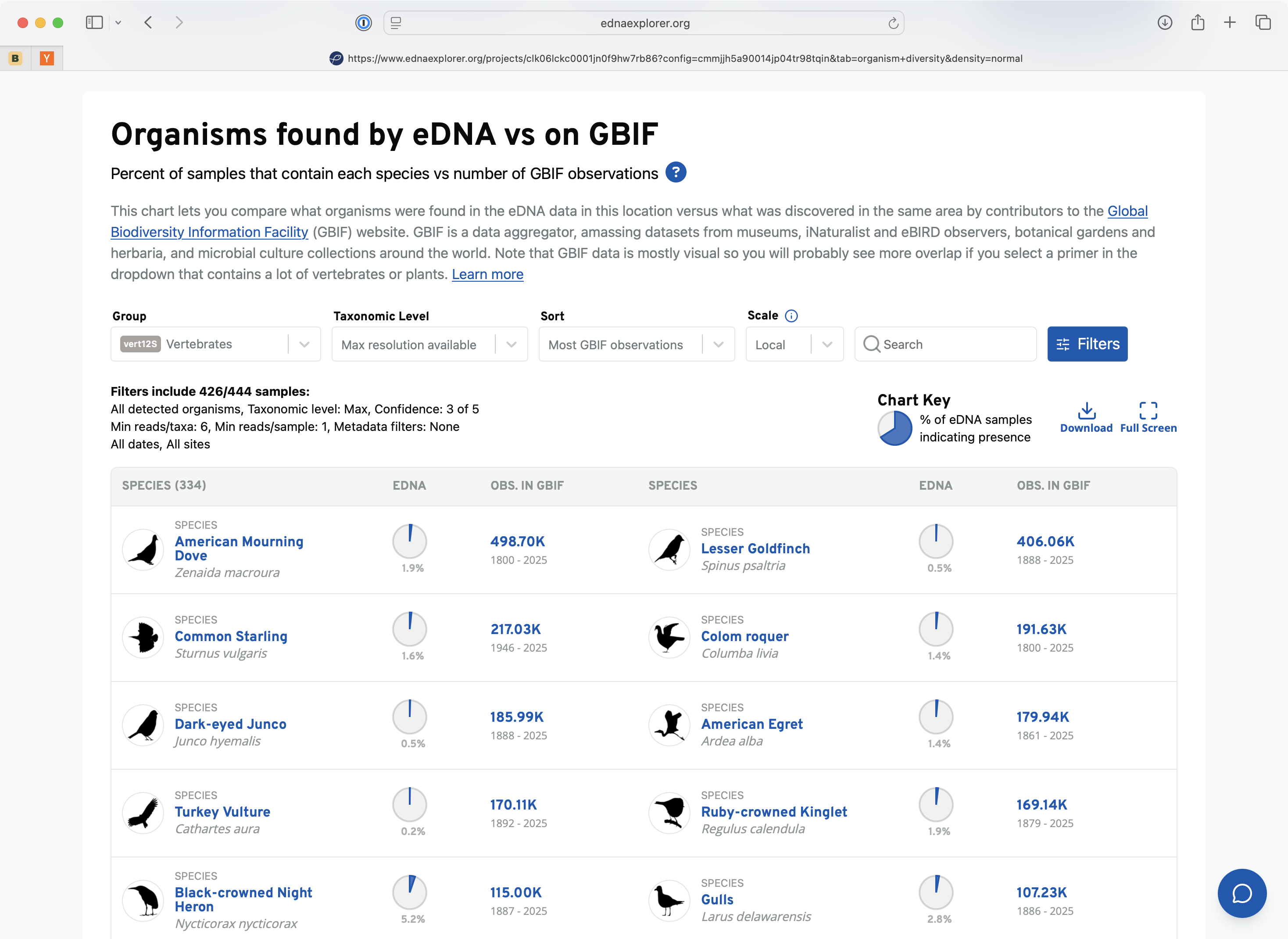
From Grant-Funded Project to Company
eDNA Explorer began as a grant-funded research collaboration. I came on as the lead engineer, responsible for implementing the UX concept into a workable web application. Things quickly escalated and I was put in charge of architecting the entire service while a separate engineering team continued to iterate on the prototype of our bioinformatics pipeline.
After the initial project shipped in 2023, the team incorporated as a formal company. I stepped into the CTO role to set technical direction, lead engineering hiring, and architect the platform. We had deployed what was a single-purpose research tool in the cloud and needed to migrate toward infrastructure that could support a broad community of conservationists, agencies, and academic researchers. The software we utilize and the nature of genomics work demanded high memory / high compute workflows so I chose to migrate our workflow to AWS EKS w/ Karpenter (now called EKS Auto Mode to compete with GKE Autopilot). We had limited revenue and funding so the trade off to utilize nodes purely on demand and pay for the wait time of cold starts was worth it. Some of these jobs would take several hours to run.
Migrating to a First-Class Orchestration Tool
By mid-way 2024 we realized observability was still lacking. Rolling our own solutions for logging as a pain point - especially given the lack of maintenance performed on the tools we depended on. I decided we needed to use an orchestrator. Our team evaluated Airflow, Dagster, and Prefect and ultimately settled on Dagster due to its declarative asset lineage. In 2025 we shipped the dagster managed version of our pipeline on Google Cloud Project due to their startup program. Below you can see how our architecture evolved into its current implementation:
Throughout this entire process we’ve continued to harden and enhance the service with automated ML modeling assets, enhanced geospatial layering, and consistent improvements to the UX of our web based reporting tools. This was a transformative year for us thanks to AI. I was an early adopter of Claude Code in the Spring. By the end of August I had nearly the entire team converted from Cursor to Claude Code. And by the end of the year everyone who touched the project had utilized agentic workflows to contribute including our CEO.
The Metabarcoding Pipeline
The core engine that powers our entire service is having a reliable, accurate, and performant pipeline to process eDNA metabarcoding samples that can operate at scale. The pipeline takes raw sequencing reads directly from a given lab and pipes them through a series of bioinformatic steps. We perform quality control, primer trimming, ASV inference, and perform taxonomic assignment against our reference databases. We enrich the data with ecological context from GBIF and iNaturalist while simultaneously building a comprehensive GIS dataset based off the sample metadata. This data is ingested into our data warehouse (Google big query) and smaller pre-processed parquet datasets are stored for our reporting service to deliver on end-user queries.
What I Built
- A platform for our customers. Starting from zero, I architected a full production platform in the form of a TypeScript monorepo. Our junior team members were able to rapidly iterate on React components for the nextJS application via storybook. I chose tRPC out of developer convenience to ship sooner rather than later.
- A sustainable AI native team of 6 experts in fullstack web dev, devops, bio-informatics, and AI/ML. I took steps to get out of the way and empower team members to own parts of the stack to achieve our company goals related to performance and accuracy. Everyone was onboarded to agentic coding in July and August of 2025 utilizing the Research, Plan, Implement methodology.
- A culture of continuous improvement from the earliest days of my involvment managing the company I championed daily stand-ups and built robust CI into our monorepo. I provide monthly mentorship to our team and coordinate continuuous learning within the company. I found this to be increasingly important as more of the coding is handed off to agentic tools. The team members need a better understanding of the abstractions outside of the code itself to better guid their planning and decision making.
- A robust genomics pipeline as mentioned above the core engine of this entire service is the genomics pipeline that allows us to operate as a Platform as a Service building a proprietary genomics dataset. The end result is a pipeline that can cost effectively process over 10,000 samples per day end-to-end.
- Pushing the state of the art via big swings with agentic coding tools. The tools for environmental DNA are compute heavy and written in low level languages. Over a weekend with Claude Code I successfully reduced the memory footprint of our primary taxonomic assignment tool by 50% and reduced the startup time from 30+ minutes. to 1.2 seconds via creation of a binary format for our reference libraries. This set an example and empowered the AI team which has ran with this idea to ambitious projects on even more robust tools.
Impact
Today eDNA Explorer is the largest dataset of its kind. We are still in the very early days of environmental DNA adoption. The platform is actively used by over 350 researchers around the planet and has been the engine behind restoration projects for organizatoins such as Dudek, Clean Water Service, River Partners, and the California Department of Fish and Wildlife.